Aligning large language models with human preferences (RLHF) has become increasingly important to ensure safety and overall usefulness of the model. Traditionally, the alignment of language models hinges upon the training objective defined as
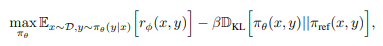
where D is the collection of training data, πθ is the policy being optimized, πref is the reference model that is usually a supervised fine-tuned LM (SFT policy), and rϕ(x, y) denotes the Reward Model (RM) that is trained in line with human preferences.
Recent methods such as The Direct Preference Optimization (DPO) reformulates the optimization task of RLHF and eliminates the Reward Model while tacitly maintaining the requirement for the policy to be close to the SFT policy.
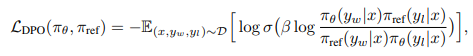
with the dataset D consisting of tuples (x, yw, yl) in which x represents a text prompt, while yw and yl stand for the human annotator’s preferred and less preferred continuations, respectively
This practice prompts us to question: Why does the reference model remain static during training ?
To address this researchers have introduced a novel conceptualization of the training process for alignment algorithms, dubbed Trust Region Direct Preference Optimization (TR-DPO). TR-DPO features updating the reference policy during training—either by softly integrating πθ into πref using a weighted approach or by outright replacing the reference policy with πθ after a predetermined number of steps.
Traditionally, vanilla DPO uses a fixed reference policy during the training, where as TR-DPO update it either with soft-update for which parameters of πθ are merged into parameters of πref with some weight α, or with hard-update (right) for which we copy parameters of πref into reference policy once in a predetermined number of training steps.
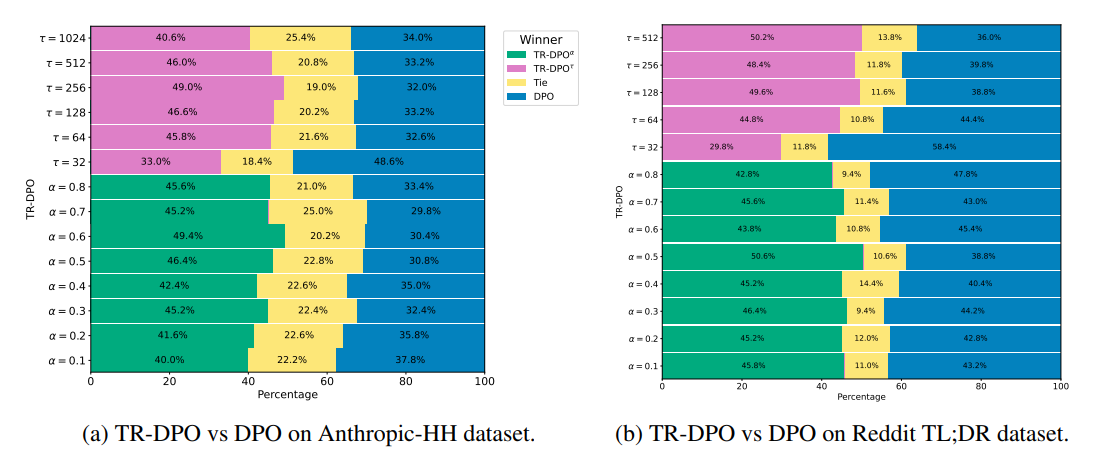
During evaluation of TR-DPO against DPO on the Anthropic HH and TLDR datasets. TR-DPO outperforms DPO by up to 19%, measured by automatic evaluation with GPT-4. The new alignment approach that we propose allows us to improve the quality of models across several parameters at once, such as coherence, correctness, level of detail, helpfulness, and harmlessness.