The Llama 3.1 release marked a big milestone for LLM researchers and the open source AI community. Meta engineers trained Llama 3.1 on NVIDIA H100 Tensor Core GPUs. They significantly optimized their full training stack and pushed model training to over 16K H100 GPUs, making the 405B the first Llama model trained at this scale.
To scale training for such a large model across 16K GPU, Meta uses 4D parallelism—a combination of four different types of parallelism methods—to shard the model: (1) Tensor parallelism [TP] (2) Pipeline parallelism [PP] (3) Context parallelism [CP] and (4) Data parallelism [DP].
Tensor parallelism splits individual weight tensors into multiple chunks on different devices. Pipeline parallelism partitions the model vertically into stages by layers, so that different devices can process in parallel different stages of the full model pipeline. Context parallelism divides the input context into segments, reducing memory bottleneck for very long sequence length inputs. Data parallelism, which shards the model, optimizer, and gradients while implementing data parallelism which processes data in parallel on multiple GPUs and synchronizes after each training step.
So how does this 4D parallelism work ?
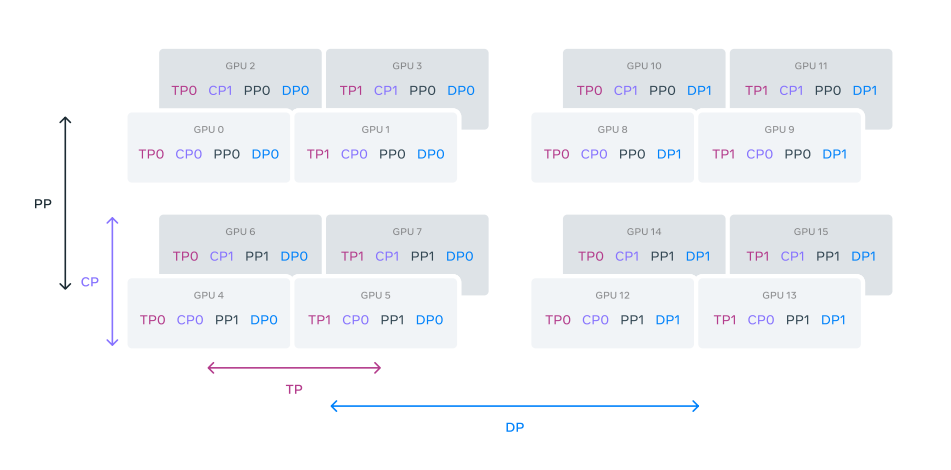
To understand this, let’s take an example of 16 GPUs clusters where GPUs are divided into parallelism groups in the order of [TP, CP, PP, DP], where DP stands for FSDP. Further, this 16 GPUs are configured with a group size of |TP|=2, |CP|=2, |PP|=2, and |DP|=2. A GPU’s position in 4D parallelism is represented as a vector, [D1, D2, D3, D4], where Di is the index on the i-th parallelism dimension. GPU0[TP0, CP0, PP0, DP0] and GPU1[TP1, CP0, PP0, DP0] are in the same TP group, GPU0 and GPU2 are in the same CP group, GPU0 and GPU4 are in the same PP group, and GPU0 and GPU8 are in the same DP group.
Paper : https://lnkd.in/dufwtswu