Large language models (LLMs) with large model size can greatly improve task performance but demand expensive computational resources for training. To address this, the LLM communities started releasing smaller-scale models like 7-B and sub-3B versions, maintaining performance parity with larger predecessors like OpenFlamingo and LLaVA series.
Now more efforts on exploring various ways for efficient training, applying sparse MoE, freezing or lora tuning backbones and deploying in terms of using such tiny LLMs have started and TinyLLaVA is one such effort. TinyLLaVA framework that provides a unified perspective in designing and analyzing small-scale Large Multimodal Models (LMMs). Study shows the effects of different vision encoders, connection modules, language models, training data and training recipes.
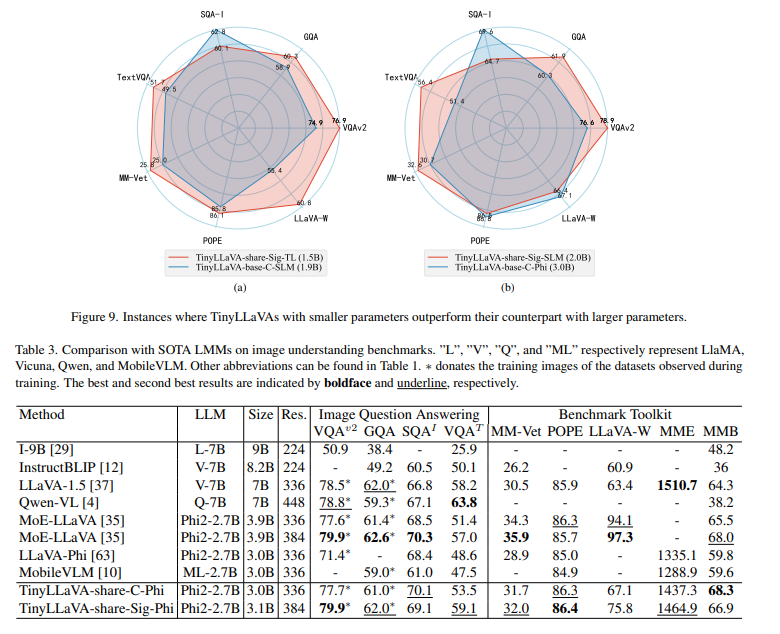
Experiments show that with better training recipes and quality of data, smaller LMMs can achieve on-par performance with larger counterparts, setting new baselines for the research field. Finally it presents a family of small scale LMMs, encompassing three language models: Phi2 , StableLM-2, and TinyLlama, and two vision encoders: CLIP, and SigLIP. Best model, TinyLLaVA-3.1B, achieves better overall performance against existing 7B models such as LLaVA-1.5 and Qwen-VL. Hope these findings can serve as baselines for future research in terms of data scaling, training setups and model selections.