In December 2023, “Mamba : Linear-Time Sequence Modeling with Selective State Spaces” paper was release and with it the whole discussion about Mamba (SSM) been a viable replacement for Transformer base model had started as Mamba achieved 4-5x higher throughput than a Transformer of a similar size. To capitalize on this, there is a growing trend of re-implementing various transformer based LLMs on Mamba (SSM) architecture such as MoE-Mamba and VMamba.
Looks like Token free LLM is also going in this direction. Typically, Token-free language models learn directly from raw bytes and remove the bias of subword tokenization. Operating on bytes, however, results in significantly longer sequences, and standard autoregressive Transformers scale poorly in such settings. Look no further, we have MambaByte to save.
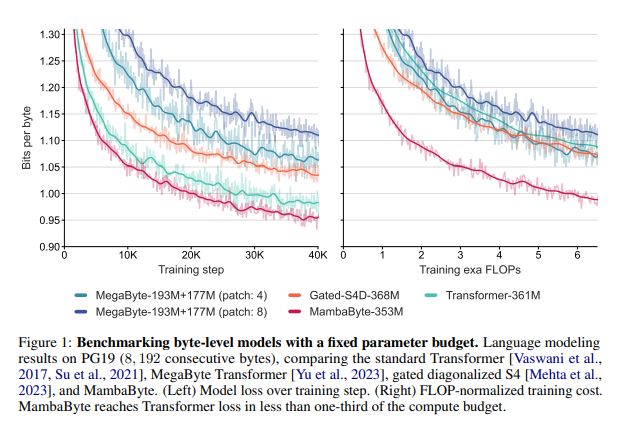
MambaByte, a token-free adaptation of the Mamba state space model, trained autoregressive on byte sequences. MambaByte eliminates the need for patching and achieves better performance and computational efficiency compared to bite level Transformers. MambaByte being a straightforward adaptation of the Mamba architecture, utilizes a linear time approach for sequence modeling by incorporating a selection mechanism that is more effective for discrete data like text section parallel scans for linear recurrences
MambaByte outperforms other byte-level models over several datasets and shows competitive results with subword Transformers, thus serving as a promising tokenization alternative. SSMs also enable significantly fast text generation due to their recurrent nature, making byte models practical.