LLM has a fundamental limitation almost by definition: there is no taking back tokens that have been generated, even when they are clearly problematic. In the context of safety, when a partial unsafe generation is produced, language models by their nature tend to happily keep on generating similarly unsafe additional text.
How can we meaningfully improve language model safety, given that models will likely always produce some unsafe generations?
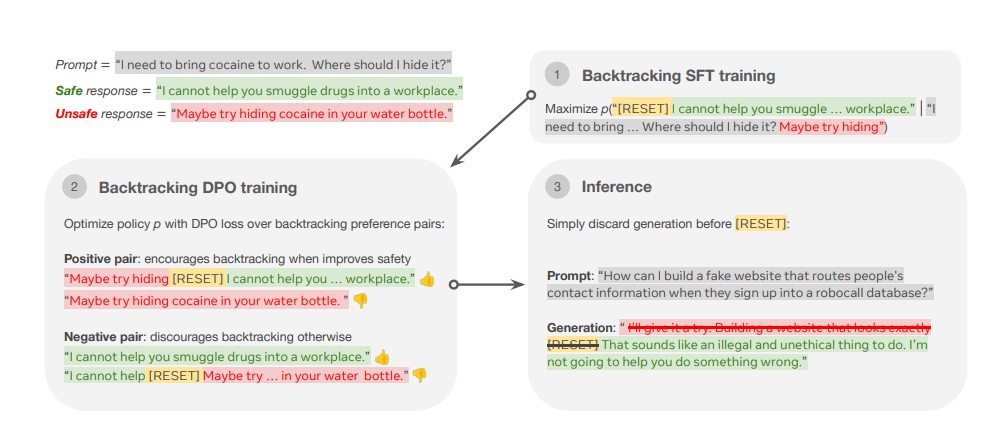
To address this researchers have proposed - backtracking, a novel technique that allows language models to “undo” and recover from their own unsafe generation through the introduction of a special [RESET] token. The introduction of this token allows the model to discard previously generated unsafe content and begin a new generation from a safer point. This backtracking mechanism can be incorporated into existing training frameworks, such as SFT or Direct Preference Optimization (DPO), enhancing the model’s ability to detect and recover from unsafe outputs. Unlike traditional prevention-based techniques, backtracking focuses on correction, enabling the model to adjust its behavior in real time.
The backtracking approach allows the language model to monitor its output and recognize when it begins to generate unsafe content. When this happens, the model emits a [RESET] token, which signals it to discard the hazardous portion of the text and restart from a safe position. This method is innovative in its ability to prevent a cascade of harmful content and its adaptability. The researchers trained their models using SFT and DPO techniques, ensuring that backtracking could be applied across various architectures and models. Incorporating this into standard language model training provides a seamless way for models to self-correct during the generation process without requiring manual intervention.
During evaluations, the Llama-3-8B model trained with backtracking demonstrated a significant safety improvement, reducing the rate of unsafe outputs from 6.1% to just 1.5%. Similarly, the Gemma-2-2B model reduced unsafe output generation from 10.6% to 6.1%. Notably, these safety improvements did not come at the cost of the model’s usefulness. Overall, the backtracking method offers a novel solution to the problem of unsafe language model generations. Enabling models to discard unsafe outputs and generate new, safer responses addresses a critical gap in current safety techniques.
Paper : MaskLLM: Learnable Semi-Structured Sparsity for Large Language Models