While Transformers have revolutionized deep learning, their quadratic attention complexity hinders their ability to process infinitely long inputs. One of the widely used approaches to handle long context inputs is Sliding Window Attention or Block Sliding Window Attention (BSWA).
During inference, LLMs allocates KV cache twice the window length at the beginning, and then using a ring buffer to update the necessary components at each step, in order to avoid memory allocation and copying operations every step, which are computationally expensive. With SWA or BSWA only a fixed ring buffer (block size + memory segment) needs to cache, which keeps memory usage constant regardless of token length enabling LLMs to generate tokens of infinite length. However, TransformerBSWA has a limited receptive field, approximately equal to the model depth × window size. This means later generated tokens may not be related to tokens outside this receptive field, such as the prompt.
To address this limitation, researchers have proposed a novel Transformer architecture called Feedback Attention Memory (FAM) or TransformerFAM in short that enables attention to both homogeneous sequence data and latent representations via a feedback loop. This architecture change fosters the natural emergence of working memory within Transformers allowing it to process indefinitely long sequences.
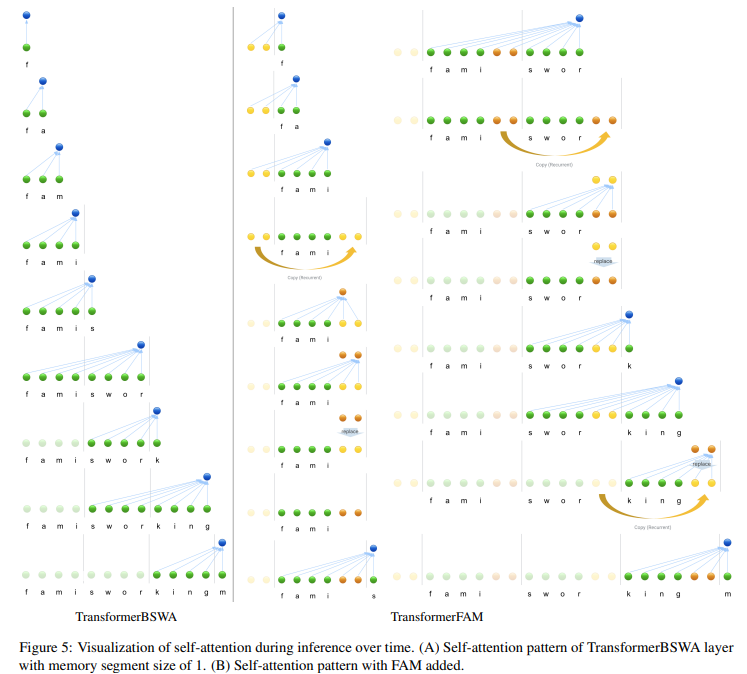
To understand it better we require to see attention patterns in the Transformer layer. In TransformerBSWA, input query attends to the current block and two memory segments, providing past context whereas in TransformerFAM input query attends to the current block, memory segments, and past FAM. FAM query (copied from previous FAM) compresses the current block to update FAM. This feedback loop enables information compression and propagation over indefinite horizon, which is working memory.
During evaluation TransformerFAM outperformed TransformerBSWA on all the long context tasks (LCT), and on various model sizes (1B, 8B, and 24B) regardless of the number of memory segments in BSWA. It shows a significant performance improvement on Scrolls Qasper and NarrativeQA, where it has to understand 5k to 500k tokens of context before answering a question. The LCT results demonstrate that TransformerFAM can effectively compress and retain important contextual information within extremely long contexts. Further, TransformerFAM requires no additional weights, enabling seamless integration with pre-trained models.