With the increasing complexity of generative AI models, post-training quantization (PTQ) has emerged as a promising solution for deploying hyper-scale models on edge devices such as mobile devices and TVs. Existing PTQ schemes, however, consume considerable time and resources, which could be a bottleneck in real situations where frequent model updates and multiple hyper-parameter tunings are required. As a cost effective alternative, one-shot PTQ schemes have been proposed. Still, the performance is somewhat limited because they cannot consider the inter-layer dependency within the attention module, which is a very important feature of Transformers.
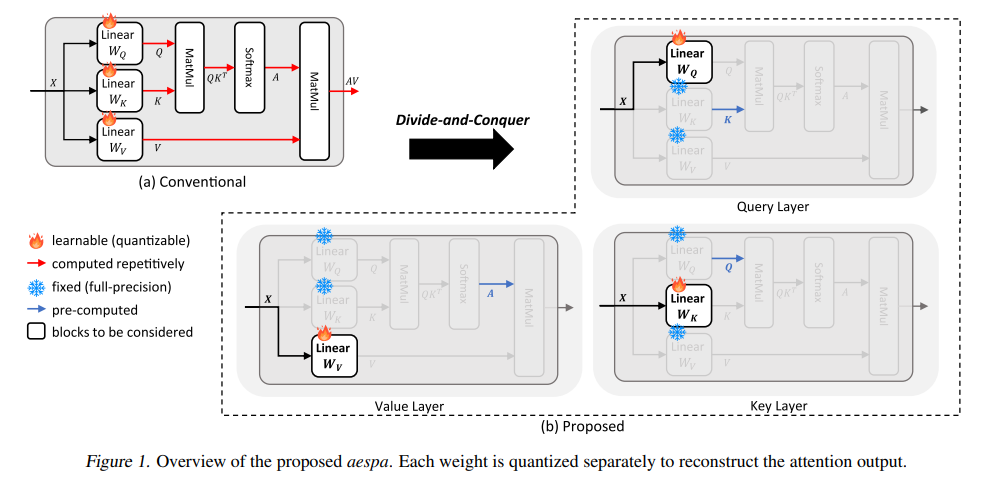
To address this paper propose a novel post-training quantization algorithm, called attention-centric efficient and scalable post-training quantization algorithm (Aespa), that pursues both accuracy and efficiency. The key idea of Aespa is to perform quantization layer-wise for efficiency while considering cross-layer dependency by refining quantization loss functions to preserve the attention score. To accelerate the quantization process, a refined quantization objectives for the attention module is been propose. Through a complexity analysis, it was demonstrate that it is about 10 times faster quantization than existing block-wise approaches can be achieved by exploiting the proposed objectives.
Experimentation on various LLMs including OPT, BLOOM, and LLaMA demonstrates that Aespa approach outperforms conventional quantization schemes such as RTN, QPTQ and Z-Fold by a significant margin, particularly for low-bit precision (INT2).