Auto-regressive decoding has become the de facto standard for large language models (LLMs). This process generates output tokens one at a time, which makes the generation by LLMs both costly and slow. Speculative sampling based methods offer a solution to this challenge. They divide the generation process of LLMs into two stages: the draft stage, where potential tokens are conjectured at a low cost, and the verification stage, where these tokens are validated in parallel through a single forward pass of the LLM.
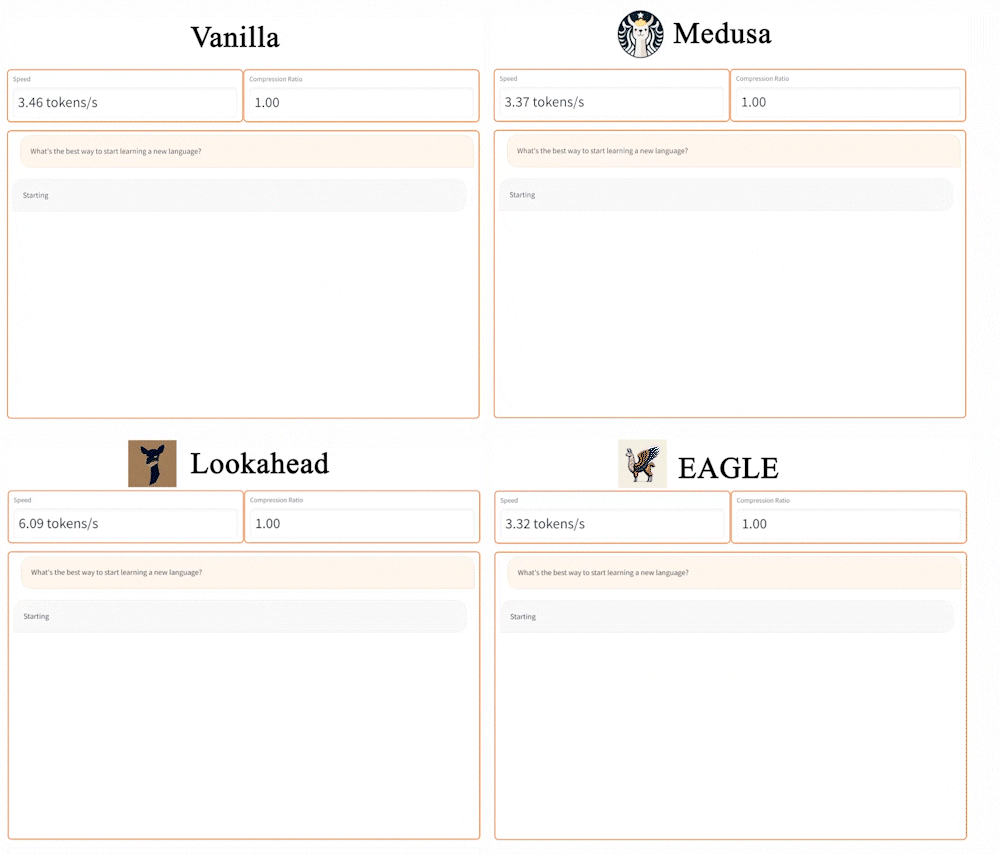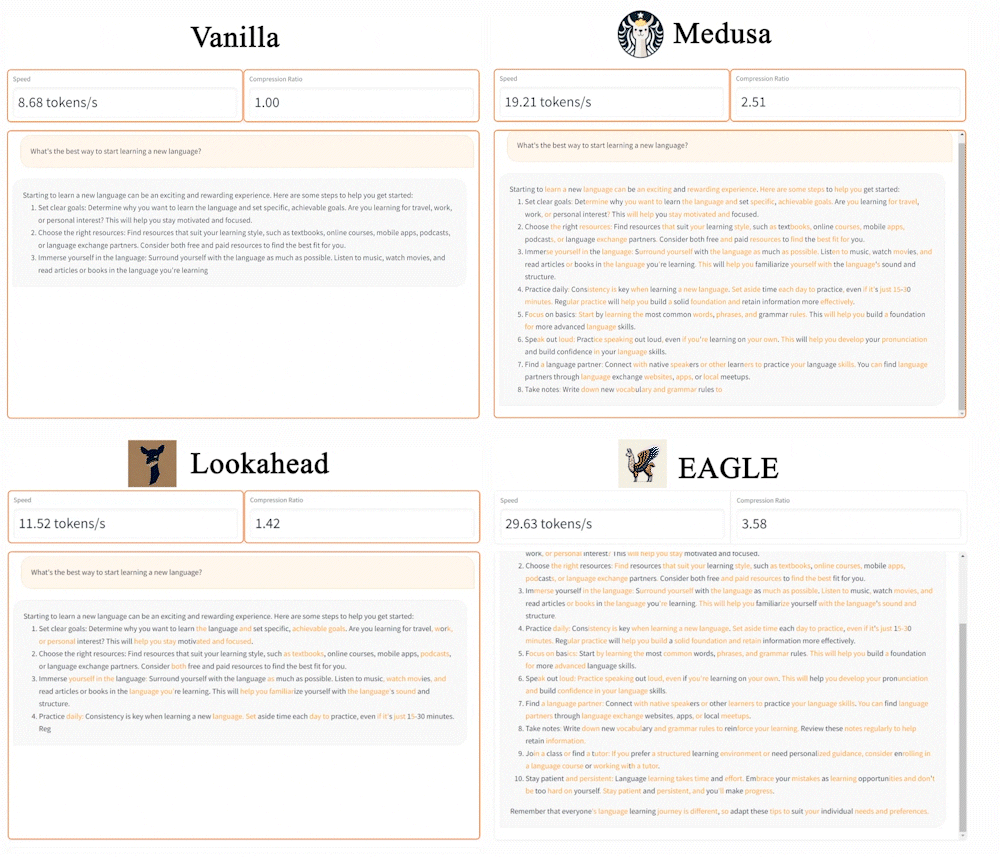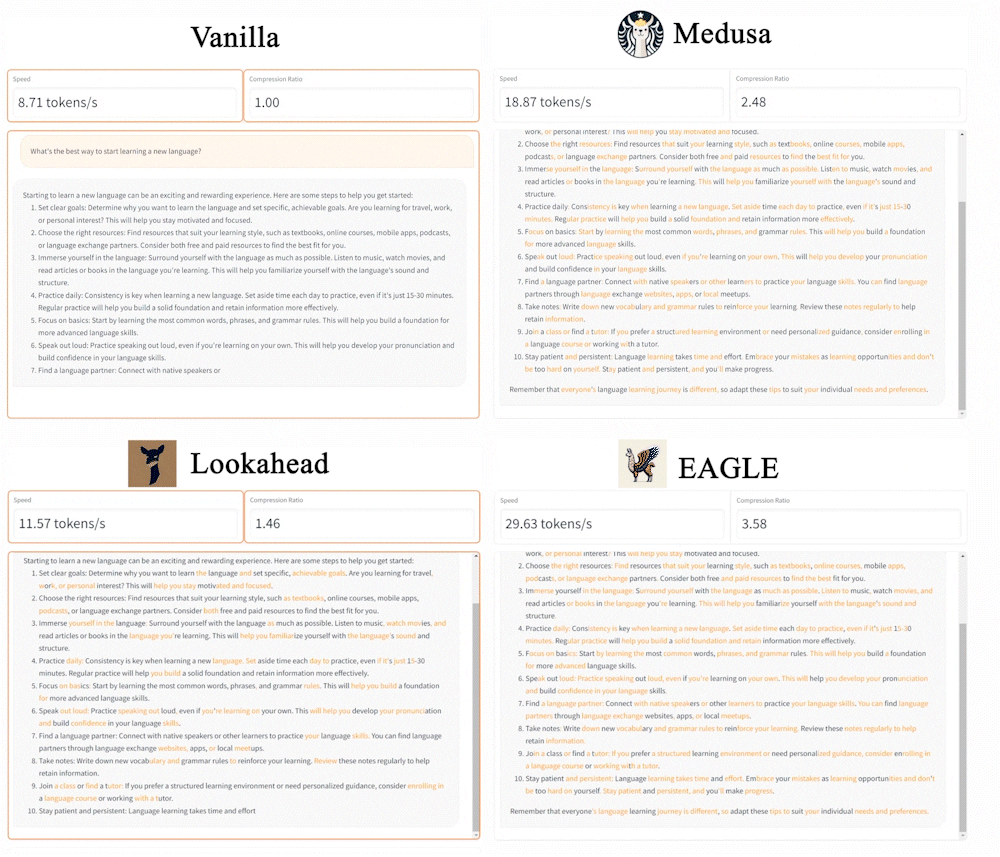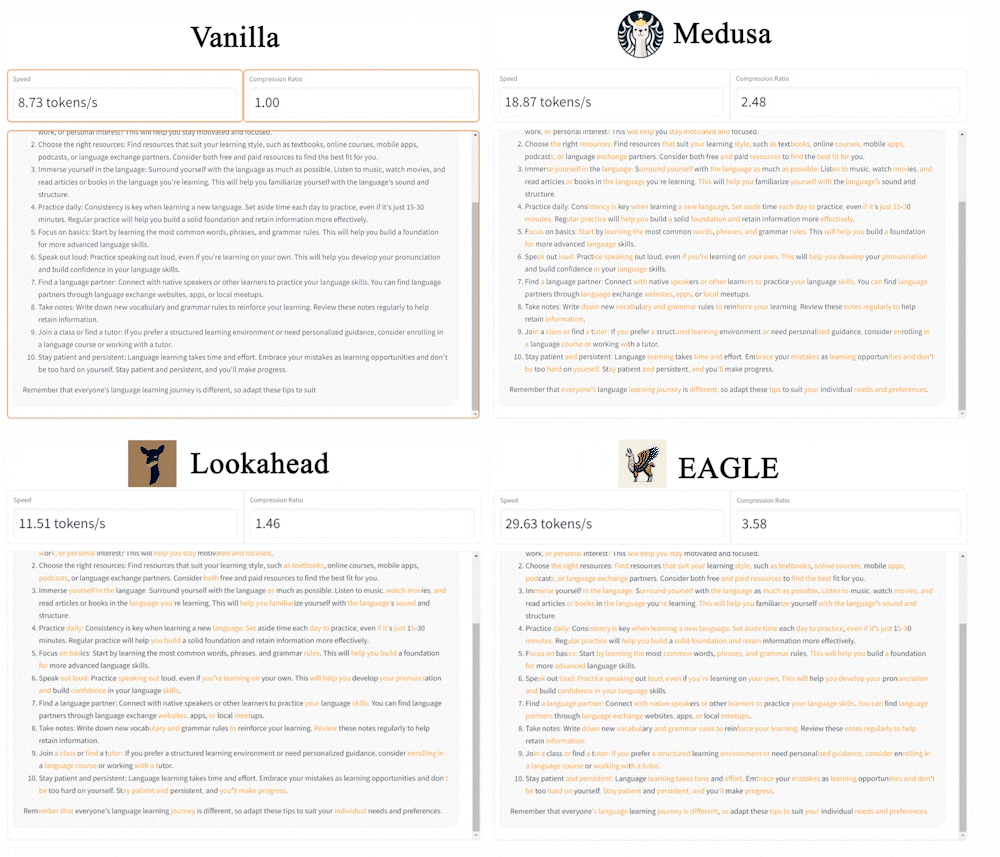
Speculative sampling aims to accelerate generation by minimizing time overhead and increasing the acceptance rate of drafts generated by the original Large Language Model (LLM). Popular methods like Lookahead and Medusa achieve this by reducing overhead and enhancing acceptance rates. Nonetheless, their full potential is limited by the lower accuracy of the drafts they generate.
EAGLE (Extrapolation Algorithm for Greater Language-model Efficiency), is a simple framework for lossless acceleration. Unlike traditional speculative sampling methods, EAGLE operates the drafting process auto-regressively at the more regular (second-top-layer) feature level and addresses the sampling uncertainty issues in the next-feature prediction problems by integrating tokens from one time step ahead. The acceleration provided by EAGLE is lossless: it involves no fine-tuning of the target LLM, and the generated text maintains the same distribution as that of vanilla auto-regressive decoding.
Compared with existing speculative sampling-based techniques, the advantages of EAGLE include:
Simplicity: EAGLE adds only a lightweight plug-in (a single transformer decoder layer) to the LLM, which can be easily deployed in a production.
Reliability: EAGLE does not involve any fine-tuning of the original LLM, and the preservation of the output distribution by EAGLE is theoretically guaranteed for both the greedy and non-greedy settings. This is in sharp contrast to Lookahead and Medusa which focuses on greedy settings only.
Speed: EAGLE stands out as the fastest framework within the family of speculative sampling. On MT-bench, EAGLE is 3x faster than vanilla decoding, 2x faster than Lookahead, and 1.6x faster than Medusa. Using gpt-fast, EAGLE attains on average 160 tokens/s with LLaMA2-Chat 13B on a single RTX 3090 GPU, compared to 24 tokens/s of Huggingface’s implementations.