Retrieval-Augmented Generation (RAG) leverages retrieval tools to access external databases, thereby enhancing the generation quality of large language models (LLMs) through optimized context. However, the existing retrieval methods are constrained inherently, as they can only perform relevance matching between explicitly stated queries and well-formed knowledge, but unable to handle tasks involving ambiguous information needs or unstructured knowledge. Consequently, existing RAG systems are primarily effective for straightforward question-answering tasks.
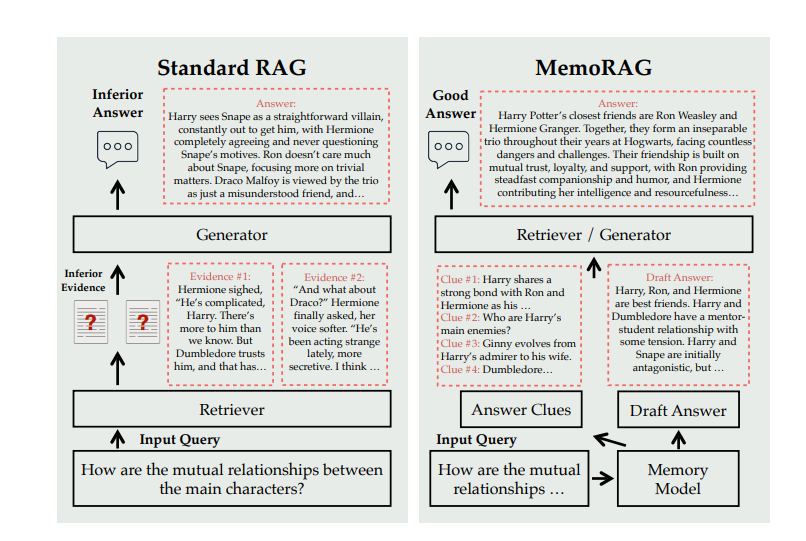
To address this researchers have proposed MemoRAG, a novel retrieval augmented generation paradigm empowered by long-term memory. For a given input query Standard RAG struggles to accurately locate the necessary evidence due to the implicit nature of the input query, resulting in a less accurate answer. Whereas, MemoRAG constructs a global memory over the whole database. When presented with the query, MemoRAG first recalls relevant clues, enabling useful information to be retrieved and thus leading to a precise and comprehensive answer.
To achieve this MemoRAG adopts a dual-system architecture. On the one hand, it employs a light but long range LLM to form the global memory of the database. Once a task is presented, it generates draft answers, cluing the retrieval tools to locate useful information within the database. On the other hand, it leverages an expensive but expressive LLM, which generates the ultimate answer based on the retrieved information.
During experiment, MemoRAG achieves superior performance across a variety of evaluation tasks, including both complex ones where conventional RAG fails and straightforward ones where RAG is commonly applied.
Paper : https://arxiv.org/pdf/2409.05591