Despite the advance of large language models (LLMs) in various applications, it still faces significant challenges to propagate further due to high computational and storage demands. Knowledge Distillation (KD) has emerged as an effective strategy to improve the performance of a smaller LLM (i.e., the student model) by transferring knowledge from a high-performing LLM (i.e., the teacher model). The primary challenges in enhancing the performance of KD approaches on LLMs stem from two main aspects: (1) appropriately utilizing the data (2) stabilize the distillation process. Thus the right domain-specific data mixtures for KD is extremely critical for overall LLM performance.
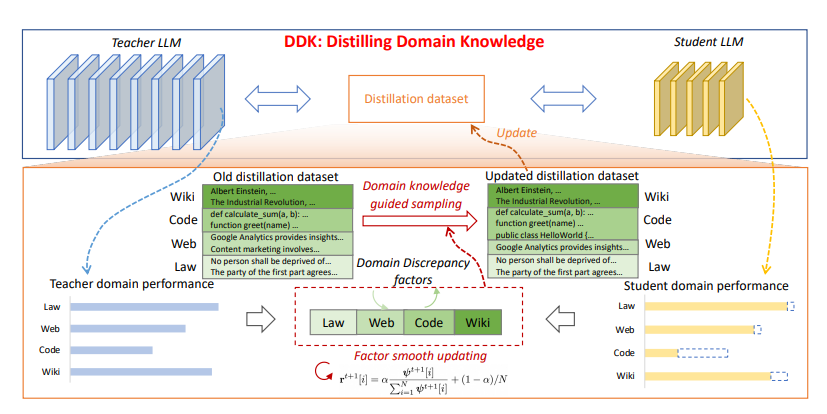
To address this researchers have introduced Distill Domain Knowledge for LLMs (DDK), a novel methodology, which is designed to improve the performance of language models by addressing the gap between teacher and student models in different domains. It works by first measuring performance differences using a validation dataset, then recalculating these discrepancies periodically. DDK uses a guided sampling strategy to focus on data from various domains according to these discrepancies. Additionally, it incorporates a factor smooth updating mechanism to enhance stability and robustness. The goal is to reduce differences in output between the teacher and student models through minimized supervision loss.
Overall first, the training dataset is divided into distinct domains based on predefined criteria. Then, DDK dynamically modulates the distribution of domain-specific data, augmenting the amount allocated to domains where the student model struggles the most. The proportions attributed to each domain are recalculated at distillation intervals by employing a factor smooth updating approach.
Extensive evaluations show that DDK significantly improves the performance of student models, outperforming both continuously pretrained baselines and existing knowledge distillation methods by a large margin.
Paper : https://arxiv.org/pdf/2407.16154