LLM Training and finetuning are still far too computationally and memory intensive tasks. Several techniques have been proposed to reduce these memory requirements, such as GaLore, gradient checkpointing, reversible backpropagation, parameter-efficient finetuning, quantization and activation offloading. While these methods are promising and lower the memory cost, they also might introduce a substantial computational overhead, are limited in their memory savings, or require specialized hardware.
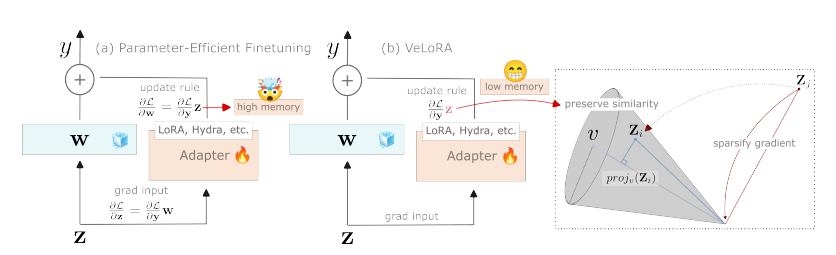
To address these challenges researchers have introduced a novel approach for efficient training and finetuning, called Vector projected LoRA (VeLoRA). VeLoRA simply divides the tokens up into smaller sub-tokens before projecting them onto a fixed 1-dimensional subspace during the forward pass. These features are then coarsely reconstructed during the backward pass to implement the update rules. By compressing and then reconstructing the activations on the fly, VeLoRA reduces the peak activation memory footprint to a tiny fraction of what is required to store the original activations. This enables fitting much larger models into limited GPU memory compared to approaches like GaLore or gradient checkpointing.
VeLoRA memory-efficient algorithm consists of two components: (i) The grouping strategy to divide the original high-dimensional tokens into much smaller sub-tokens; and (ii) Fixed rank-1 projections of these sub-tokens using cheap heuristically initialized principal components. Given a large pre-trained model, above steps are applied to compress the intermediate activations saved during training while preserving most of the original model’s training dynamics.
VeLoRA was evaluated on both moderately-sized vision transformers as well as in large language models. VeLoRA was found to significantly reduce memory requirements while improving the performance effectiveness on VTAB-1K, MMLU, GLUE, and C4 benchmarks outperforming state-of-the-art methods such as LoRA, QLoRA or GaLore.
Paper : https://arxiv.org/pdf/2405.17991