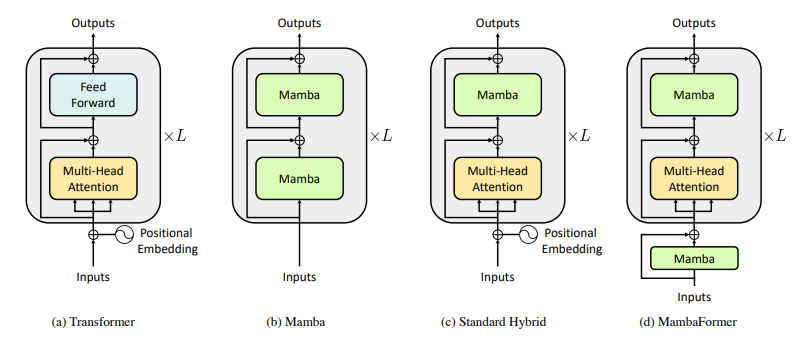
State-space models (SSMs), such as Mamba, have been proposed as alternatives to Transformer networks in language modeling, by incorporating gating, convolutions, and input-dependent token selection to mitigate the quadratic cost of multi-head attention. Although SSMs exhibit competitive performance, against Transformer models in standard regression in-context learning (ICL) tasks, it falls short in more complex ICL tasks like Vector-valued MQAR. To address these limitations, the paper has introduced a hybrid model, MambaFormer, that combines Mamba with attention blocks, surpassing individual models in tasks where they struggle independently.
Before jumping to MambaFormer lets us have a deepdive at in-context learning (ICL). In-context learning (ICL) has emerged as one of the most remarkable capabilities of LLMs like GPT-3 and GPT-4. With just a few demonstration examples (few-short learning), these models can rapidly adapt to new tasks and make accurate predictions without any parameter updates. Numerous research studies have been dedicated to understanding the mechanics of Attention in transformer models that enable such meta-in-context-learning capabilities, either through constructive arguments or extensive experimental investigation. Transformer language models are currently the only large models that have been reported to be capable of ICL in practice.
So Can attention-free models perform ICL?
Well that’s what this paper tries to address. Series of experiment against Transformer, Mumba and MumbaFormer LLMs was carried out for various ICL task such as Linear regression, Sparse linear regression, 2NN regression, Decision Tree, Orthogonal-outlier regression, Many-outlier regression , Sparse parity, Chain-of-Thought I/O and Vector-valued MQAR. MumbaFormer has been the winner in all these tasks. So what is this MambaFormer ?
MambaFormer is a hybrid architecture that replaces MLP blocks within the transformer with Mamba blocks. Importantly, the architecture also starts with a Mamba block and does not use positional encoding. During ICL evaluations, it was found that MambaFormer consistently achieves a best-of-both-worlds performance compared to Transformer and Mamba.