Large language models (LLMs) have achieved substantial progress in processing long contexts but still struggle with long-context reasoning. Existing approaches typically involve fine-tuning LLMs with synthetic data, which depends on annotations from human experts or advanced models like GPT-4, thus restricting further advancements.
So can LLMs self improve in long-context reasoning ?
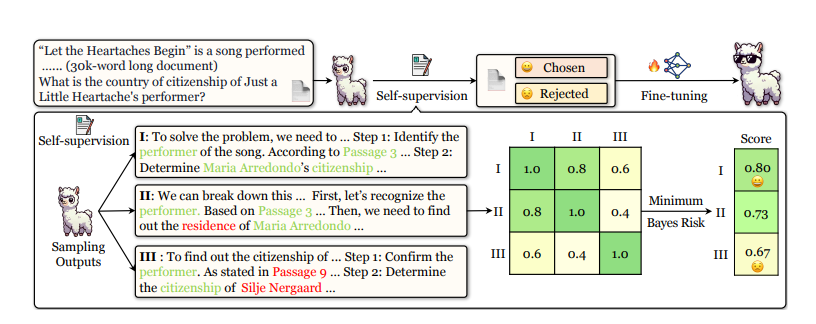
To address this issue, researchers have proposed a Self-improving method for rEAsoning over LONGcontexts (SEALONG). SEALONG consists of two stages: self-supervision creation and fine-tuning. Given a long context and a corresponding query, multiple outputs are sampled, each assigned a score based on Minimum Bayes Risk. Fine-tuning is then conducted using either the highest-scoring output for supervised fine-tuning or both high-scoring and low-scoring outputs for preference optimization. The idea is that reasoning paths differing from the majority are more likely to be hallucinations. Based on this, one can improve model performance by either fine-tuning with high-quality outputs or using preference optimization that incorporates both high- and low-quality outputs.
Extensive experiments on several leading LLMs demonstrate the effectiveness of SEALONG. Specifically, SEALONG raises the score of Llama-3.1-8B Instruct from 50.8 to 55.0. Additionally, SEALONG enabled Qwen-2.5-14BInstruct to outperform its 32B variant In comparison to previous synthetic data, SEALONG demonstrated notable improvement without requiring human or expert model annotation.
Paper : Large Language Models Can Self-Improve in Long-context Reasoning