The attention mechanism is a critical component of Large Language Models (LLMs) that allows tokens in a sequence to interact with each other, but the attention mechanism inherently lacks ordered information and treats sequences as sets. Thus, it is necessary to have an additional mechanism for encoding position information. Position encoding (PE) achieves this by assigning an embedding vector to each position and adding that to the corresponding token representations.
In order to tie position measurement to more semantically meaningful units such as words, or sentences, one needs to take context into account. However, this is impossible with current PE methods as position addressing is computed independently of the context, and thus cannot generalize to higher levels of abstraction, such as attending to the i-th sentence.
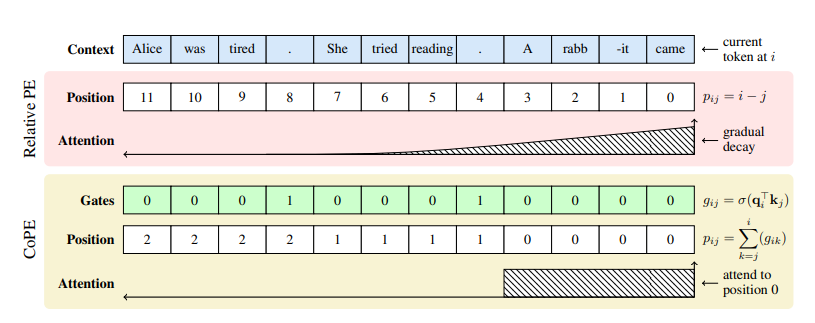
To address these challenges researchers have proposed a new position encoding method, Contextual Position Encoding (CoPE), that allows positions to be conditioned on context by incrementing position only on certain tokens determined by the model. This allows more general position addressing such as attending to the i-th particular word, noun, or sentence.
CoPE first determines which tokens to count using their context vectors. Specifically, given the current token as a query vector, CoPE computes a gate value for each previous token using their key vectors. Then it aggregates those gate values to determine the relative position of each token with respect to the current token. Unlike token positions, this contextual position can take fractional values, thus cannot have an assigned embedding. Instead, it interpolate embeddings that are assigned to integer values to compute position embeddings. Like the other PE methods, these position embeddings are then added to the key vectors, so a query vector can use them in the attention operation. Since contextual position can vary from query-to-query and layer-to-layer, the model can simultaneously measure distances in multiple units.
During evaluation CoPE were applied to several toy tasks: counting, selective copying and the Flip-Flop task, where it outperforms token-based PE methods, especially in the case of out-of-domain generalization. To test real-world applicability, a language modeling task on Wikipedia text where applied with CoPE leading to better performance. The same performance gain is also observed when trained on code.
Paper : https://arxiv.org/pdf/2405.18719