Segment Anything Model 2 (SAM 2) has emerged as a powerful tool for video object segmentation and tracking anything. Key components of SAM 2 that drive the impressive video object segmentation performance include a large multistage image encoder for frame feature extraction and a memory mechanism that stores memory contexts from past frames to help current frame segmentation. The high computation complexity of multistage image encoder and memory module has limited its applications in real-world tasks, e.g., video object segmentation on mobile devices.
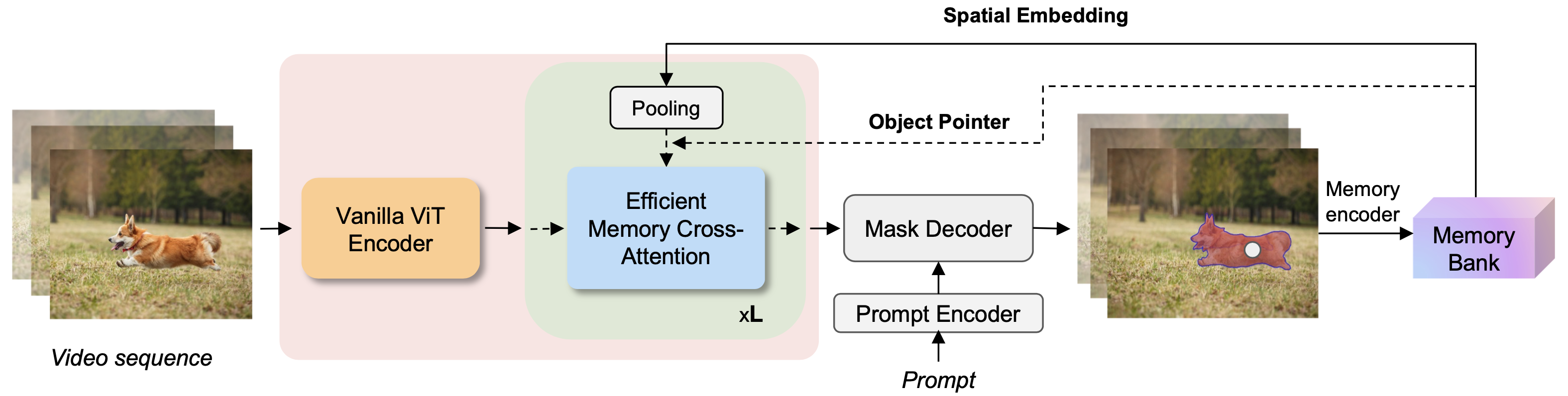
To address this limitation, researchers from meta have proposed EfficientTAMs, lightweight track anything models that produce high-quality results with low latency and model size.EfficientTAM takes a vanilla lightweight ViT image encoder for frame feature extraction. An efficient memory cross-attention is then used to further improve the efficiency of EfficientTAM by leveraging the strong locality of memory spatial embeddings, which reduces the complexity for both frame feature extraction and memory computation for current frame segmentation. EfficientTAM is fully trained on SA-1B (image) and SA-V (video) for unified image and video segmentation.
During evaluation on multiple video segmentation benchmarks including semi supervised VOS and promptable video segmentation, EfficientTAM with vanilla ViT perform comparably to SAM 2 model (HieraB+SAM 2) with ∼2x speedup on A100 and ∼2.4x parameter reduction. On segment anything image tasks, EfficientTAMs also perform favorably over original SAM with ∼20x speedup on A100 and ∼20x parameter reduction. On mobile devices such as iPhone 15 Pro Max, EfficientTAMs can run at ∼10 FPS for performing video object segmentation with reasonable quality, highlighting the capability of small models for on-device video object segmentation applications.
Paper : Efficient Track Anything