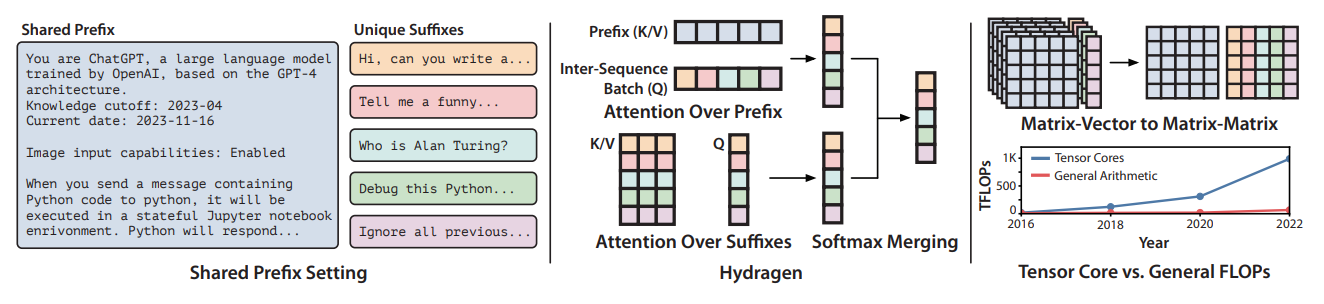
Transformer-based large language models (LLMs) such as OpenAI GPT3.5 and GPT4 are now deployed to hundreds of millions of users. LLM inference in such scenarios commonly performed on batches of sequences that share a prefix (the system prompt), such as few-shot examples or a chatbot system prompt. Decoding in this large-batch setting can be bottlenecked by the attention operation, which reads large key-value (KV) caches from memory and computes inefficient matrix-vector products for every sequence in the batch. Even with FlashAttention and PagedAttention models redundantly read the prefix’s keys and values from GPU memory when computing attention, regardless of whether the prefix is redundantly stored.
In order to eliminate these redundant reads paper introduce Hydragen, a hardware-aware exact implementation of attention with shared prefixes. Hydragen computes attention over the shared prefix and unique suffixes separately. This decomposition enables efficient prefix attention by batching queries together across sequences, reducing redundant memory reads and enabling the use of hardware-friendly matrix multiplications.
Let’s take an example of LLM chat model inference, which processes many sequences that share a large shared prefix (the system prompt). With Hydragen overall attention is decomposed into attention over the shared prefix (batched across all queries in a batch) and attention over the remaining suffixes (independent across sequences, as is normally done). Hydragen’s attention decomposition allows many matrix vector products to be replaced with fewer matrix-matrix products. Using matrix-matrix products is particularly important as GPUs dedicate an increasingly large ratio of their total FLOPs to tensor cores that are specialized in matrix multiplication
In end-to-end benchmarks, Hydragen increases the throughput of CodeLlama-13b by up to 32x over vLLM, a high-performance inference framework that avoids redundant prefix storage but not redundant prefix reads. Hydragen also enables the use of very long shared contexts: with a high batch size, increasing the prefix length from 1K to 16K tokens decreases Hydragen throughput by less than 15%, while the throughput of baselines drops by over 90%. Hydragen generalizes beyond simple prefix-suffix decomposition and can be applied to tree-based prompt sharing patterns, allowing us to further reduce inference time on competitive programming problems by 55%.