The Transformer architecture is backbone of any production LLMs, but despite its remarkable capabilities, it faces challenges with quadratic computational complexity and limited inductive bias for length generalization, making it inefficient for long sequence modeling.
Techniques like efficient attention mechanisms and structured state space models (SSM) have been introduced to overcome these limitations, aiming to enhance scalability and performance. However, the practical application of these methods empirically underperform Transformers in pretraining efficiency and downstream task accuracy.
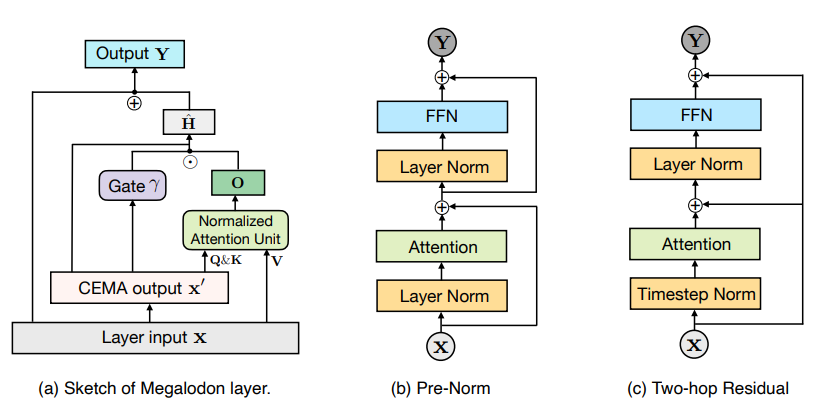
To address this researchers have introduced MEGALODON, an improved MEGA architecture (exponential moving average with gated attention), which harnesses the gated attention mechanism with the classical exponential moving average (EMA). To further improve the capability and efficiency of MEGALODON on large-scale long context pre-training, multiple novel technical components have been introduced.
First, MEGALODON introduces the complex exponential moving average (CEMA) component, which extends the multi-dimensional damped EMA in MEGA to the complex domain. Then, MEGALODON proposes the timestep normalization layer, which generalizes the group normalization layer to autoregressive sequence modeling tasks to allow normalization along the sequential dimension. To improve large-scale pretraining stability, MEGALODON further proposes normalized attention, together with pre-norm with two-hop residual configuration by modifying the widely-adopted pre and post-normalization methods. By simply chunking input sequences into fixed blocks, as is done in MEGA-chunk, MEGALODON achieves linear computational and memory complexity in both model training and inference.
In a controlled head-to-head comparison with LLAMA2, MEGALODON achieves better efficiency than Transformer in the scale of 7 billion parameters and 2 trillion training tokens. MEGALODON reaches a training loss of 1.70, landing mid-way between LLAMA2- 7B (1.75) and 13B (1.67). The improvements of MEGALODON over Transformers are robust throughout a range of benchmarks across different tasks and modalities