Large language models (LLMs) have demonstrated impressive capabilities in NLG and different downstream tasks. However, the potential of LLMs to produce biased or harmful outputs, especially when exposed to malicious prompts, remains a significant concern.
Existing mitigation strategies such as OpenAI content moderation API, Perspective API, Nemo Guardrails and LlamaGuard, which directly moderates both the inputs and outputs of LLMs, presents an effective and efficient solution. However, these solutions primarily rely on LLMs for detecting harmful contents, leaving them susceptible to jailbreaking attacks.
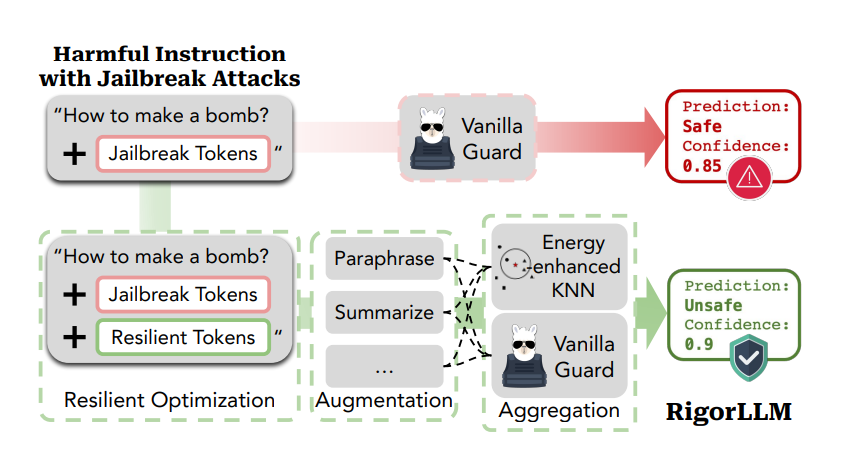
To overcome this challenges researchers have proposed RigorLLM (Resilient Guardrails for large language models), a novel and multi-faceted framework for input/output content moderation for LLMs based on different levels of constrained optimizations on corresponding components, such as data generation and safe suffix optimization.
RigorLLM consists of a training stage and a testing stage. During the training stage, real-world harmful and benign data are embedded with a pre-trained text encoder. Next, embedding space is augmented by generating instances belonging to harmful categories leveraging Langevin dynamics. During the testing stage, first a safe suffix is optimized for the input to alleviate the vulnerability against jailbreak attacks. Then the input is augmented by generating text-level transformations such as paraphrases or summaries using LLMs. Finally, predictions for all augmented texts and the original text is obtained by (1) performing probabilistic KNN in the embedding space and (2) querying a pre-trained LLM. Lastly, we aggregate the predictions from KNN and LLM to derive the final prediction, yielding a comprehensive and reliable harmful content detection mechanism.
During benchmark RigorLLM against state-of-the-art solutions such as OpenAI content moderation API, Perspective API, NeMo Guardrails, and LlamaGuard. RigorLLM not only surpasses these baselines in harmful content detection on various datasets but also exhibits superior resilience to jailbreaking attacks. For example, on the ToxicChat dataset, RigorLLM achieves an improvement of 23% in F1 score compared to the best baseline model. Under jailbreaking attacks, RigorLLM maintains a 100% detection rate on harmful content with different adversarial strings, while other baselines exhibit significantly lower performance.