Fine-tuning LLMs using Reinforcement Learning from Human Feedback (RLHF) has alway been a preferred way for making LLMs more useful by aligning them with human values or preferences. RLHF optimization toward the preference is usually done using a two-step procedure: reward learning, and policy optimization (through RL) to maximize the learned reward. RLHF fundamentally relies on the reward maximization framework, wherein reward-based preferences are governed by, e.g., the BT model.
However, this reward maximization framing poses following major limitations: (1) Reward functions, used to score responses to inputs, can’t capture complex preferences like intransitive or cyclic preferences between multiple outputs. (2) Reward functions in practice can quickly become “stale” as the distribution of the policy shifts under training leaving them vulnerable to “reward hacking (3) Even when preferences can be perfectly expressed in reward-based Behavioral Transfer (BT) models, optimizing towards rewards can lead to problematic behaviors.
To address these weaknesses, researchers from Microsoft have introduced Direct Nash Optimization (DNO), a provable and scalable RLHF algorithm that marries the simplicity and stability of contrastive learning with theoretical generality from optimizing general preferences.
Direct Nash Optimization, addresses these challenges by approximating soft policy iteration updates with a regression-based contrastive objective in a batched manner, which is a much more stable and forgiving learning objective, and establish a concentration bound of Oe( 1/N) on the squared total variation error between the learned policy and its target of the soft policy iteration update at any given iteration t. Theoretically, DNO converges to the Nash equilibrium on-average, but in practice enjoys monotonic improvement across iterations. Because DNO is a batched on-policy algorithm using a regression-based objective, its implementation is straightforward and efficient.
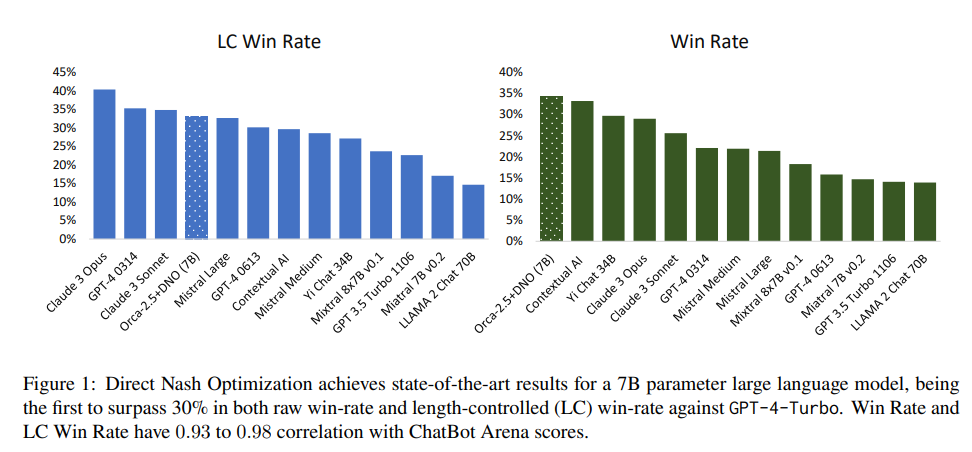
During experimentation, a 7B parameter Orca-2.5 model is aligned by DNO and achieves the state-of-the-art win-rate against GPT-4-Turbo of 33% on AlpacaEval 2.0 (even after controlling for response length), an absolute gain of 26% (7% → 33%) over the initializing model. It outperforms models with far more parameters, including Mistral Large, Self-Rewarding LM (70B parameters), and older versions of GPT-4. Moreover, DNO enjoys monotonic improvement across iterations which helps it improve even over a strong teacher (such as GPT-4).