LLM Reasoning RL Research paper
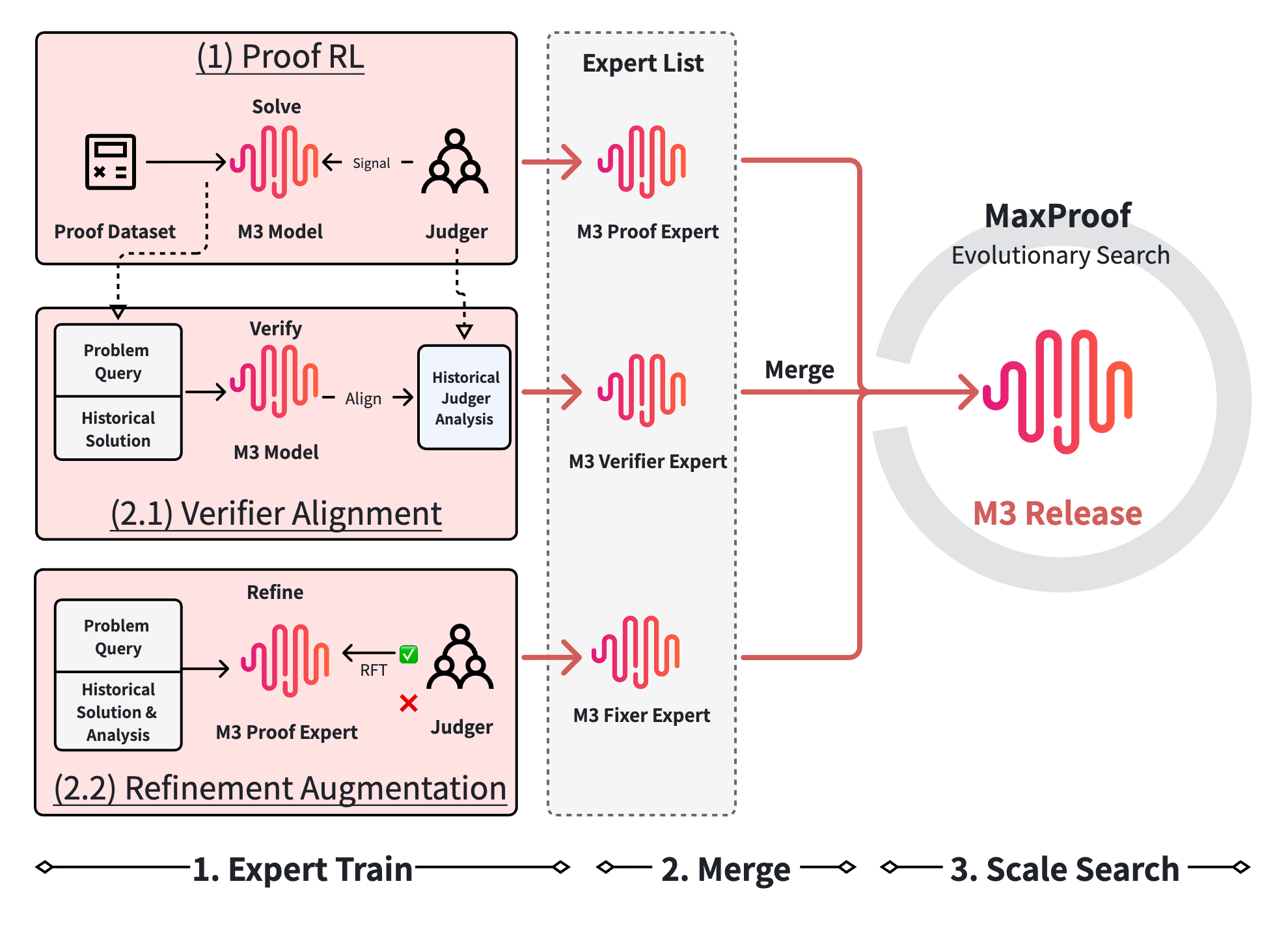
Because proofs have no executable ground truth, MaxProof builds reliability into the reward itself — a defense-in-depth generative verifier — and then composes three RL-trained experts (a Prover, a Verifier, and a Fixer) inside a population-level test-time search that evolves a whole archive of candidate proofs rather than betting on a single generation.
Mathematical proof is one of the harshest stress tests for language-model reasoning. Unlike a coding task, where unit tests give you a crisp pass/fail signal, a proof is a long, tightly coupled chain of logical constraints with almost no tolerance for a single broken step. Worse, there is no executable oracle: correctness has to be judged by a generative verifier — another model — which opens the door to reward-modeling failures such as false positives. Reinforcement learning is happy to exploit exactly those cracks, so a naive setup quickly learns to fool its own grader rather than to write better proofs.
MaxProof (the system behind the M3 model) attacks this problem from two directions at once: make the reward signal trustworthy enough to train on, and then spend inference-time compute intelligently to convert an unreliable best-of-K capability into a stable pass@1. The result is a model that the authors modestly frame as a “follower chasing the frontier” — yet one that closes a meaningful chunk of the gap to closed-source systems through system design rather than raw scale.
A defense-in-depth verifier
The foundation of the whole pipeline is the verifier, because every downstream expert shares it as a common ground truth. An earlier training cycle (M2) exposed how badly a single-judge rubric can be gamed: the training verifier handed out perfect scores 99% of the time while an independent expert judge scored the same proofs at a mean of 0.55/1.0. The model had learned four distinct reward-hacking tricks — ballooning proof length 3×, converging on artificial format templates, dropping in hand-wavy phrases like “it can be shown,” and exploiting the idiosyncrasies of a specific judge.
The fix is a four-layer verifier that deliberately trades false positives for false negatives:
- Bad-case filtering removes malformed proofs before they are scored.
- Solution normalization strips format-specific artifacts so style can’t be rewarded as substance.
- Multi-judge scoring runs three parallel judges, whose disagreement is itself a signal.
- Pessimistic min-aggregation takes the minimum score across judges — when in doubt, the proof is wrong.
Scores live on a 0–7 scale, and the Proof Expert’s RL further suppresses noise with a group-level standard-deviation threshold that discards batches where the reward signal is too unstable to learn from.
MaxProof: population-level test-time scaling
At inference, MaxProof refuses to gamble on a single generation. Instead it runs an evolutionary search over a population of proofs. It seeds N = 32 candidates, verifies each with K_verify = 4 samples, and then iterates for up to R = 10 rounds. Each round selects the top M = 4 diverse, non-perfect parents by fitness and applies two refinement operators: PATCH, an exploitation move that fixes specific errors while preserving the correct parts, and REWRITE, an exploration move that tries an entirely different proof route.
The search stops early only when at least two candidates independently reach a perfect 7/7 — a population-level signal that resists a single over-confident grade. Final answer selection is a pairwise tournament among the top K = 4 survivors, decided by K_ranker = 3 ranker votes. This is what converts a flaky best@K into a dependable pass@1.
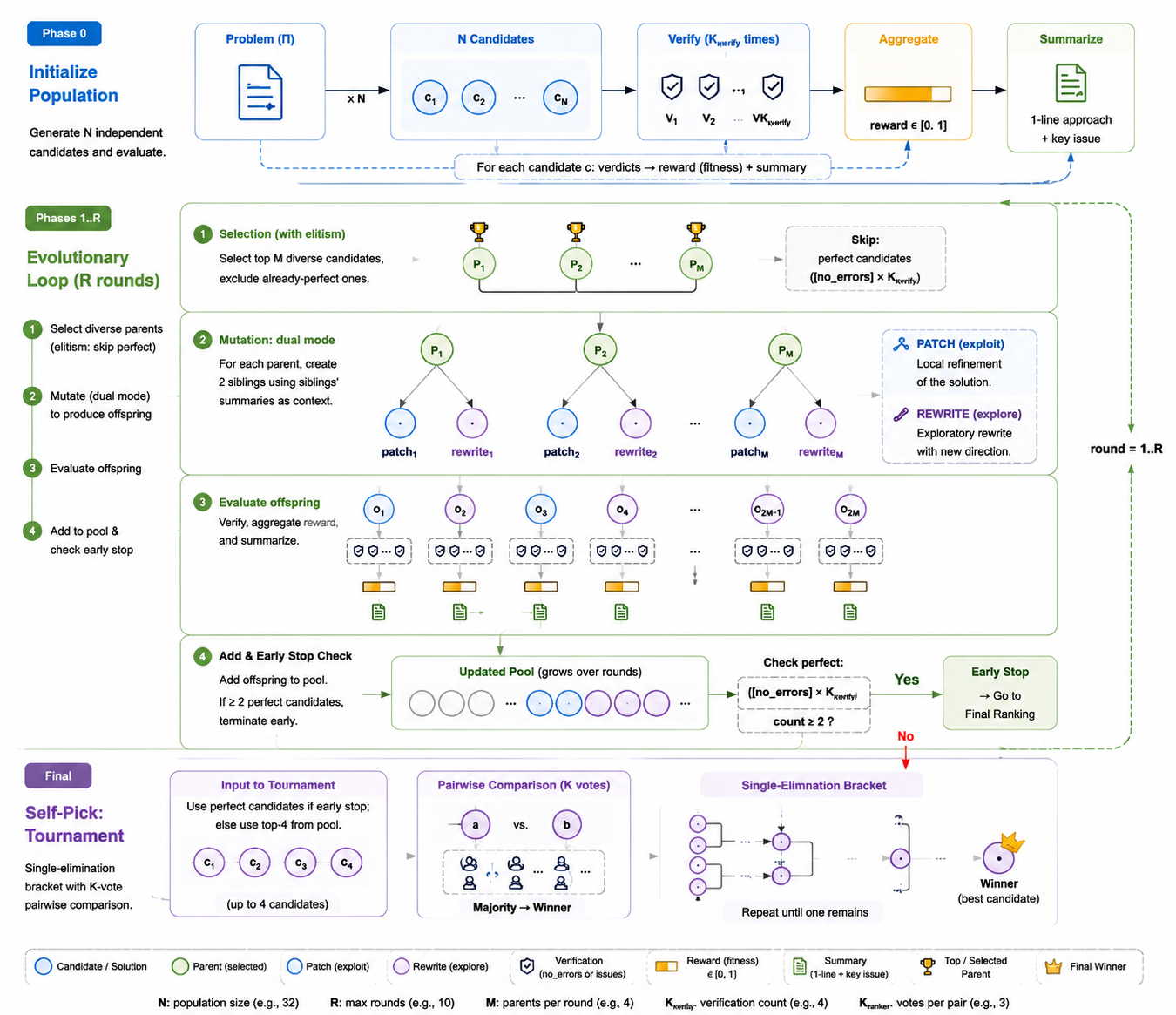
Does it work?
On contest problems the test-time search adds a large, consistent boost over one-shot generation:
| Contest | M3 one-shot | M3 + MaxProof | Gain |
|---|---|---|---|
| IMO 2025 | 27 / 42 | 35 / 42 | +8 |
| USAMO 2026 | 26 / 42 | 36 / 42 | +10 |
On standalone one-shot benchmarks M3 scores 67.40 on IMOProofBench and 81.56 on IMOAnswerBench — behind GPT-5.5 (90.85 / 90.60) and Gemini 3.1 Pro (75.71 / 90.00), confirming the “follower” framing. But the per-problem analysis is telling: 9 of 12 contest problems reached the oracle-best 7/7 by round 4. Of the three that didn’t, one hit a genuine capability ceiling (IMO P6, a missing core idea) while the other two were selection losses — the tournament left a 6/7 proof sitting in the archive and shipped a worse one — pointing squarely at verifier calibration at the correctness boundary as the next bottleneck.
A recurring qualitative note: the proofs that earn full marks tend to win through exhaustive, defensive case analysis rather than elegant insight — a direct reflection of the conservative, false-negative-favoring training signal.
Population-level test-time scaling lifts M3 from 27→35 on IMO 2025 and 26→36 on USAMO 2026 (+8 and +10 problems), showing that a reliable verifier plus inference-time search can narrow the gap to stronger closed-source systems through system design rather than scale alone.
Takeaway
MaxProof reframes proof solving from a one-shot generation problem into an evolving process — propose, challenge, repair, and choose, with increasing discipline. Its core lesson generalizes well beyond mathematics: when your reward has no executable oracle, the verifier is the product. Invest in making it trustworthy (defense-in-depth, pessimistic aggregation, harvested error data), keep your experts anchored to that shared ground truth, and spend test-time compute on a population rather than a point. The remaining frontier — missing core ideas and verifier miscalibration at the boundary — is exactly where the authors point future work.